Operators vs. GitOps:You've Been Asking the Wrong Question
Two reconciliation loops, one control plane — and why the smartest platform teams stopped picking a side

> Hot take: “Operators vs. GitOps” is a fake fight. They don’t compete. One is an engine with no source of truth; the other is a source of truth with no engine. The teams winning at scale figured this out and run both.
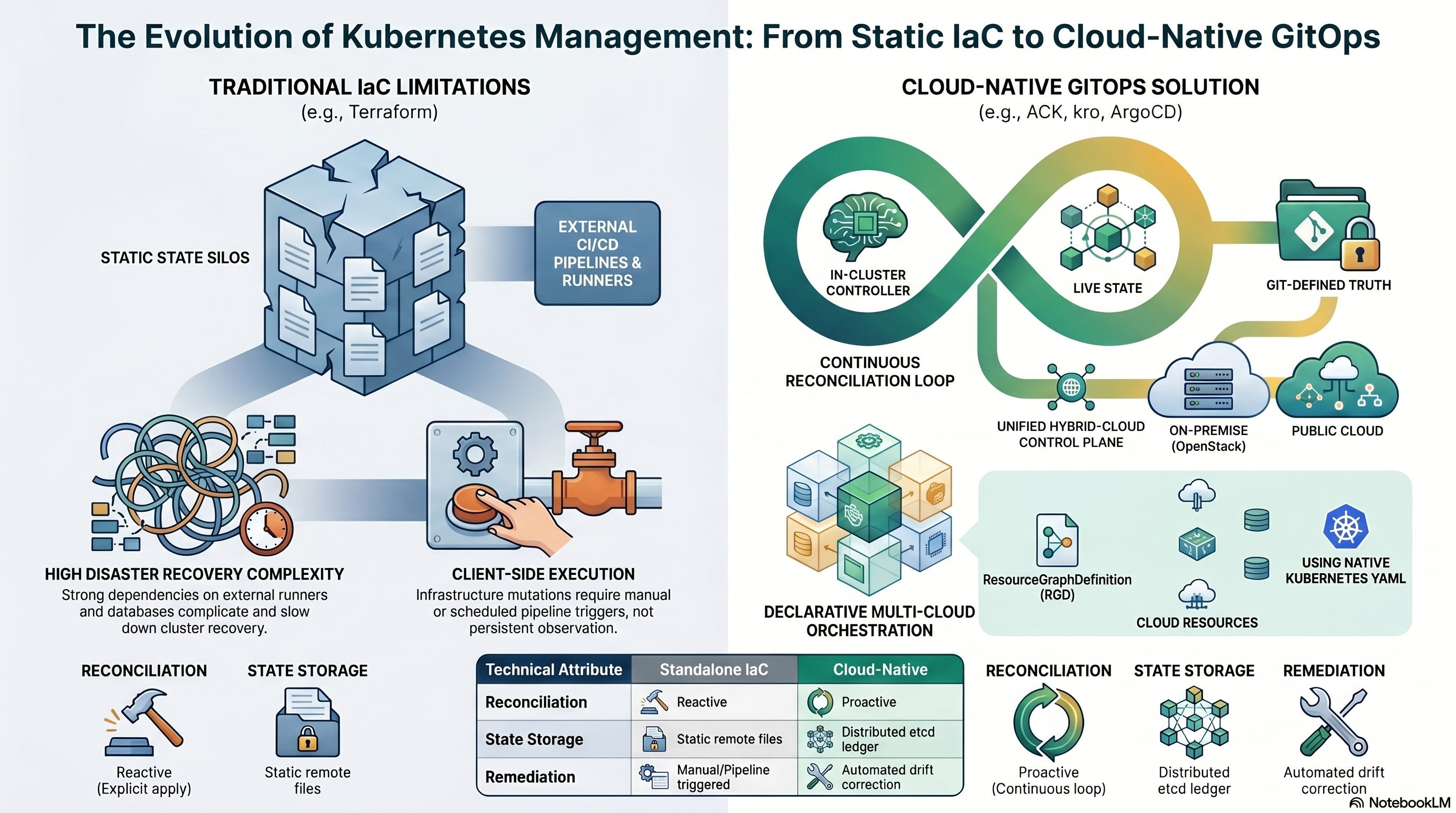
If you’ve built internal platforms, you know this argument. One camp wants to extend the Kubernetes API with custom Operators that provision infrastructure on demand. The other wants everything in Git, reconciled by Argo CD. Both sides say the same four words — declarative, desired state, reconciliation, drift — which is exactly why the debate goes in circles.
Here’s the thing nobody says out loud: they’re answering different questions.
The Operator pattern answers: who turns a desired-state object into real infrastructure?
GitOps answers: where does the desired state live, and how does it get into the cluster?
Separate those two questions and the whole argument dissolves. What looked like a rivalry turns out to be a stack. Let me show you.
What an Operator actually is
Most “Operator vs. X” arguments are really arguments about loose definitions, so let’s be strict.
Kubernetes defines the Operator pattern narrowly: software extensions that use custom resources to manage applications, following Kubernetes principles — notably the control loop. The motivation is right there in the name. It captures the aim of a human operator who knows how a system should behave, how to deploy it, and how to react when it breaks. You encode that knowledge into software.
Mechanically, an Operator is two things bolted together:
A custom resource — a new object type added to the API via a CustomResourceDefinition.
A custom controller — a process that watches those objects and acts on them.
The controller is just the standard Kubernetes control loop pointed at a new object type. Think of a thermostat: you set the target temperature (the spec), it reads the room, and it acts to close the gap. Forever. An Operator is a thermostat for whatever domain you taught it — a database, a queue, or an entire cloud provider’s API.
> The detail that unlocks infrastructure provisioning: if the desired state lives in the API server but the real resource lives outside the cluster, the controller reads its target from the API and talks directly to the external system to make reality match. The custom resource lives in etcd; the real thing lives in AWS. The controller bridges them.
ACK: the Operator pattern aimed at a cloud
AWS Controllers for Kubernetes (ACK) is the cleanest production example. It’s a collection of controllers — one per AWS service — built from CRDs that extend the Kubernetes API and manage AWS resources for you. Each watches for custom resources and calls AWS APIs to create, update, and delete the real thing.
Write this:
apiVersion: s3.services.k8s.aws/v1alpha1
kind: Bucket
metadata:
name: my-ack-bucket
spec:
name: my-unique-bucket-name…apply it, and the ACK S3 controller turns that spec into AWS API calls and creates the bucket. One CRD per resource type — Bucket, Table, Database — each mapping directly onto the resource’s real attributes.
The magic is the reconciliation loop. Someone flips a DynamoDB table from PAY_PER_REQUEST to PROVISIONED in the AWS Console? ACK notices on its next cycle and flips it right back. The cluster becomes the source of truth for the cloud resource.
(One caveat: changes you make to the Kubernetes resource hit AWS fast, but passive detection of drift made directly in AWS can lag — up to the resync period, around ten hours, though usually much sooner.)
This is powerful. Databases, queues, buckets — all managed with the same kubectl, the same RBAC, the same manifests as your workloads. No second toolchain.
But here’s the gap. ACK is an Operator: CRDs + controllers + a loop. It says nothing about where the manifest came from. That bucket gets created the instant the custom resource hits the API server — whether you kubectl apply‘d it from your laptop, a CI job pushed it, or a GitOps engine synced it. Provenance? Audit trail? Review? Rollback? Not ACK’s job.
Guess whose job that is.
GitOps: where desired state lives, and how it arrives
GitOps isn’t a Kubernetes primitive — it’s an operational discipline, formalized by the CNCF’s OpenGitOps project. The core claim: Git is the single source of truth, and an automated agent continuously reconciles the live system against what Git declares.
Argo CD is the reference implementation. It uses Git repositories as the source of truth for desired state and automates deployment into your clusters. Under the hood: an API server, a repo server that renders manifests (YAML, Helm, Kustomize, Jsonnet), and an application controller that endlessly compares Git vs. the cluster and corrects drift.
Two properties do the heavy lifting:
🔄 The pull model. Instead of a CI pipeline shoving kubectl apply in from outside, an agent inside the cluster pulls from Git. Smaller blast radius — no handing cluster-admin to external systems — and the reconciliation logic lives next to what it manages.
🩹 Continuous reconciliation + self-healing. Argo CD is always checking live state against Git. Someone hand-edits a service in the cluster? It gets reverted to match Git. And since every change is a commit, rollback is just git revert.
A precision point, because this is where GitOps gets confused with CI/CD: CI builds and tests artifacts. GitOps is the CD half — it deploys by reconciling the cluster to Git. Argo CD does deployment and reconciliation, not builds.
So GitOps closes ACK’s gap. Git holds desired state; the agent delivers it with audit, review, and rollback baked in. But GitOps leaves its own gap wide open: once the manifest’s in the cluster, who provisions the actual cloud resource? A plain Deployment? Built-in controllers handle it. An S3 bucket or an RDS instance? You need something that knows how to talk to AWS.
That something is an Operator. Which is why the honest answer to “Operators or GitOps?” is yes.
The comparison, side by side
Operator pattern (e.g. ACK)GitOps (e.g. Argo CD)What it isAPI extension: CRDs + controllersDiscipline + in-cluster sync agentThe question it answersWho provisions the real thing?Where does state live & how does it arrive?Source of truthThe custom resource (etcd)A Git repositoryReconcilesCluster ↔ external system (AWS API)Cluster ↔ GitHow state entersAgnostic — kubectl, CI, or GitOpsGit commit, pulled by the agentDrift handlingReverts cloud drift to the CR specReverts in-cluster drift to GitAudit / rollbackNone inherentNative — Git history, PRs, git revertIts blind spotWhere manifests come fromProvisioning non-native (cloud) resources
Read that last row twice. The Operator has an engine but no provenance. GitOps has provenance but no engine. Stack them and each fills the other’s hole:
> Git is the source of truth → Argo CD reconciles Git into the cluster → an Operator reconciles the resulting custom resources into real cloud infrastructure. Two reconciliation loops, chained. One guards against in-cluster drift. The other guards against cloud-side drift.
And “templatised provisioning” lives in both layers: Operator compositions fan one high-level claim out into many cloud resources; GitOps Helm / ApplicationSets fan one definition out across many apps and clusters. Real platforms use both.
What this looks like in production
Theory’s tidy. Here’s the shape it takes at scale. Teams running large multi-cluster, multi-cloud fleets — think hundreds of clusters, plus public-cloud burst capacity for scarce resources like GPUs — keep converging on the same layered architecture. Three layers, all driven by Argo CD from one central Git repo:
The “underlay” — provisioning the clusters and cloud resources themselves, via a Kubernetes-native infrastructure Operator like Crossplane (or ACK).
Cluster add-ons — monitoring, policy enforcement, cost aggregation.
End-user services — the actual application workloads.
Crossplane plays the same role ACK plays in the AWS-native story: a CNCF Operator that provisions any cloud resource via the Kubernetes API. Because a Crossplane resource is just a Kubernetes manifest, you store it in Git and let Argo CD manage it. Commit a change, Argo CD + Crossplane make it real.
And this is where the reason to combine them gets stated most clearly:
> A CI/CD pipeline can push an infrastructure change — but it doesn’t watch for drift afterward. Someone tweaks the real state and the pipeline has no idea. That’s the missing back half of the equation. Argo CD supplies it: it watches actual state and triggers reconciliation. The Operator supplies the half Argo CD lacks: it extends Kubernetes’ reconciliation loop to cloud resources.
Is it frictionless? No. Teams adopting this early hit rough edges wiring infrastructure Operators cleanly into GitOps tooling — enough that “better native integration” has been a standing community ask. Running both is the right architecture — but it isn’t turnkey. That rough edge is exactly what newer patterns target: combine ACK with a grouping layer (kro) so a dev opens a PR describing a cluster, Argo CD applies it, the grouping controller decomposes it into ordered ACK resources, and ACK assumes a role in the target account to build the real thing — EKS cluster, VPC, IAM roles. Same three-layer shape. Same division of labor.
So which do you reach for?
Drop the tribalism. It’s about which gap you’re closing.
Need cloud resources lifecycle-managed by a control loop, same API and RBAC as your workloads? → You need an Operator. ACK for AWS-only first-party coverage; Crossplane for multi-cloud + composable claims. The Operator is the thing that talks to the cloud.
Need every change reviewed, versioned, auditable, auto-reverted on drift? → You need GitOps. Argo CD (or Flux) reconciling Git. It’s the thing that gives you provenance and self-healing.
Need both? — and at real scale, you do — layer them. State in Git. Argo CD reconciles Git into the cluster and kills in-cluster drift. An Operator reconciles the custom resources into real infrastructure and kills cloud-side drift. Templatise wherever it fits.
The two patterns were never rivals. One’s an engine without a source of truth. The other’s a source of truth without an engine. The interesting platforms are the ones that stopped arguing and started chaining the loops together.
Ref:
If this was useful, I write about platform engineering, Kubernetes, and cloud infrastructure at https://nachikul.dev or https://nachikul.substack.com . Disagree with me? Even better — let’s argue in the comments.